

关于PostgreSQL
PostgreSQL 是一个强大的开源对象关系数据库系统,它使用并扩展了 SQL 语言,并结合了许多安全存储和扩展最复杂数据工作负载的功能。
PostgreSQL 是以加州大学伯克利分校计算机系开发的POSTGRES, 版本 4.2为基础的对象关系型数据库系统
PostgreSQL,也称为 Postgres,简称PG(以下都简称PG)
PG 号称是“世界上最先进的开源关系型数据库”,和“世界上最好的语言”不同,PG的自吹自擂并没有受到大家的调侃
PG 不属于任何一家公司,它背后的控制机构是——PostgreSQL全球开发小组,是一个松散的组织
其核心成员来自全球各地的不同公司,如果感兴趣,可以在PG官网查询到这个组织的成员列表
可以这么说,没有任何一个公司享有对 PG 的绝对控制权,PG永远是属于社区
协议
开源大家都不陌生,但是开源并不等于免费,下面是几种协议的区别
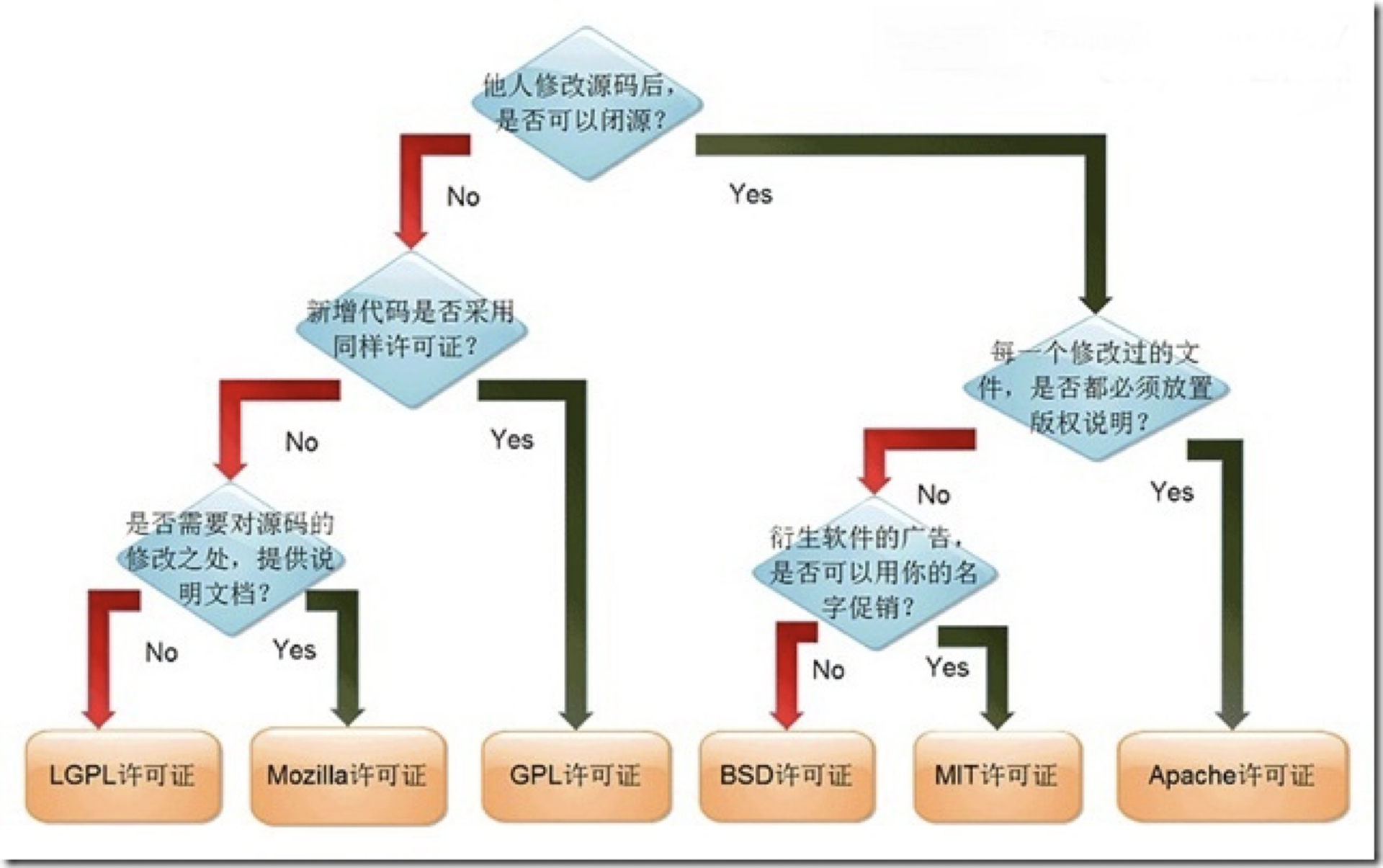
GPL 协议:
GPL 是一种传染协议,如果修改了源码,也必须使用 GPL 协议
GPL 是一种“非商业”友好协议,如果是商业项目,那一定要注意 GPL 的可能带来的问题
Linux 内核 使用的就是 GPL 协议,免费的 MySQL 社区版使用的也是 GPL 协议
BSD 协议:
BSD 是一个给予使用者很大自由的协议
基本上使用者可以“为所欲为”可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布
PG 早期使用的就是 BSD 协议,后面换成了自有协议——PostgreSQL License,虽然换了自由协议,但并没有多少改变,依然属于最为友好的协议类型
不论是自用还是商用,都是完全没有问题,修改代码并且用来盈利也是毫无商业风险的
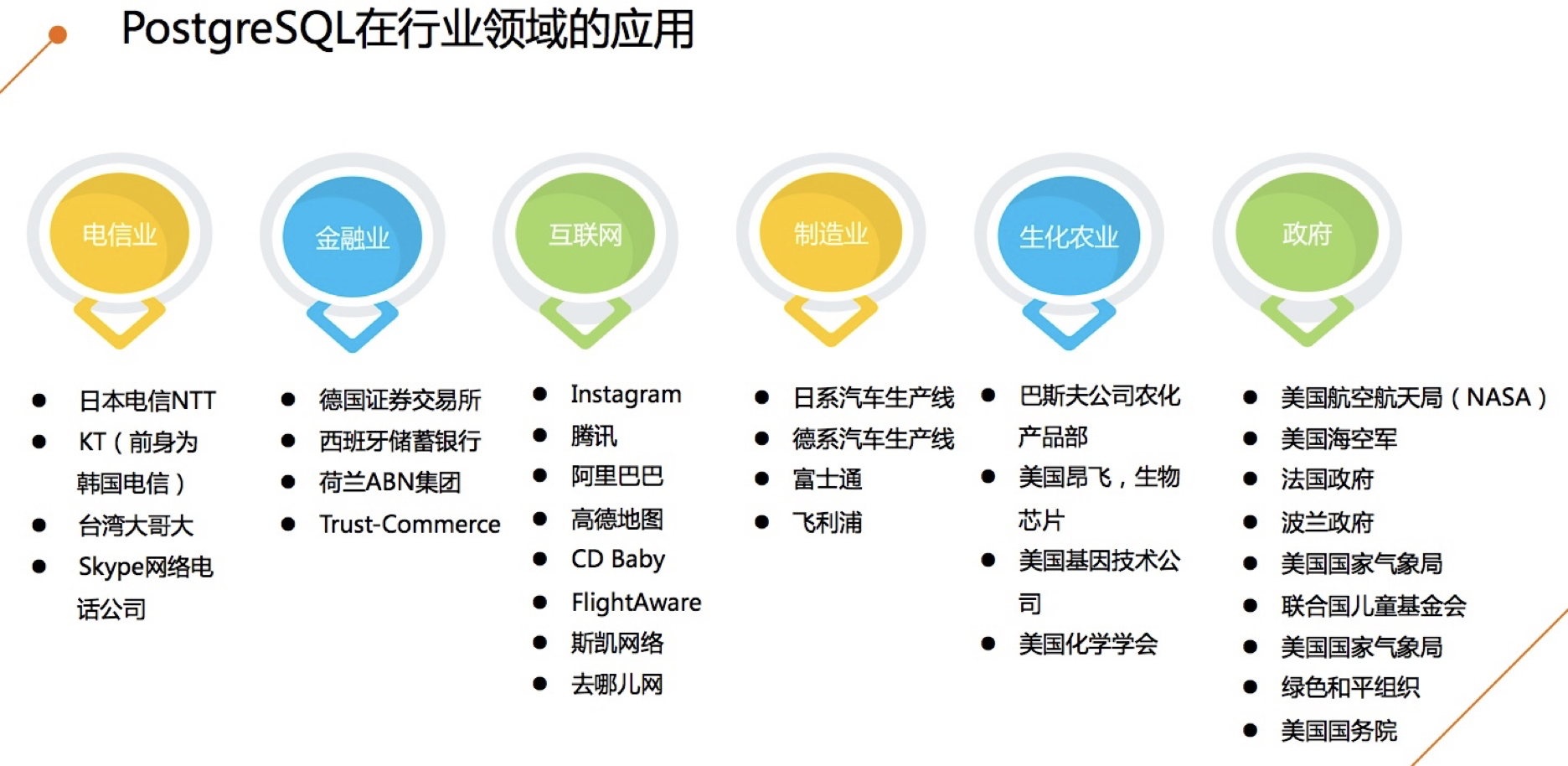
PG影响力
在行业中的应用(几年前的图)
-
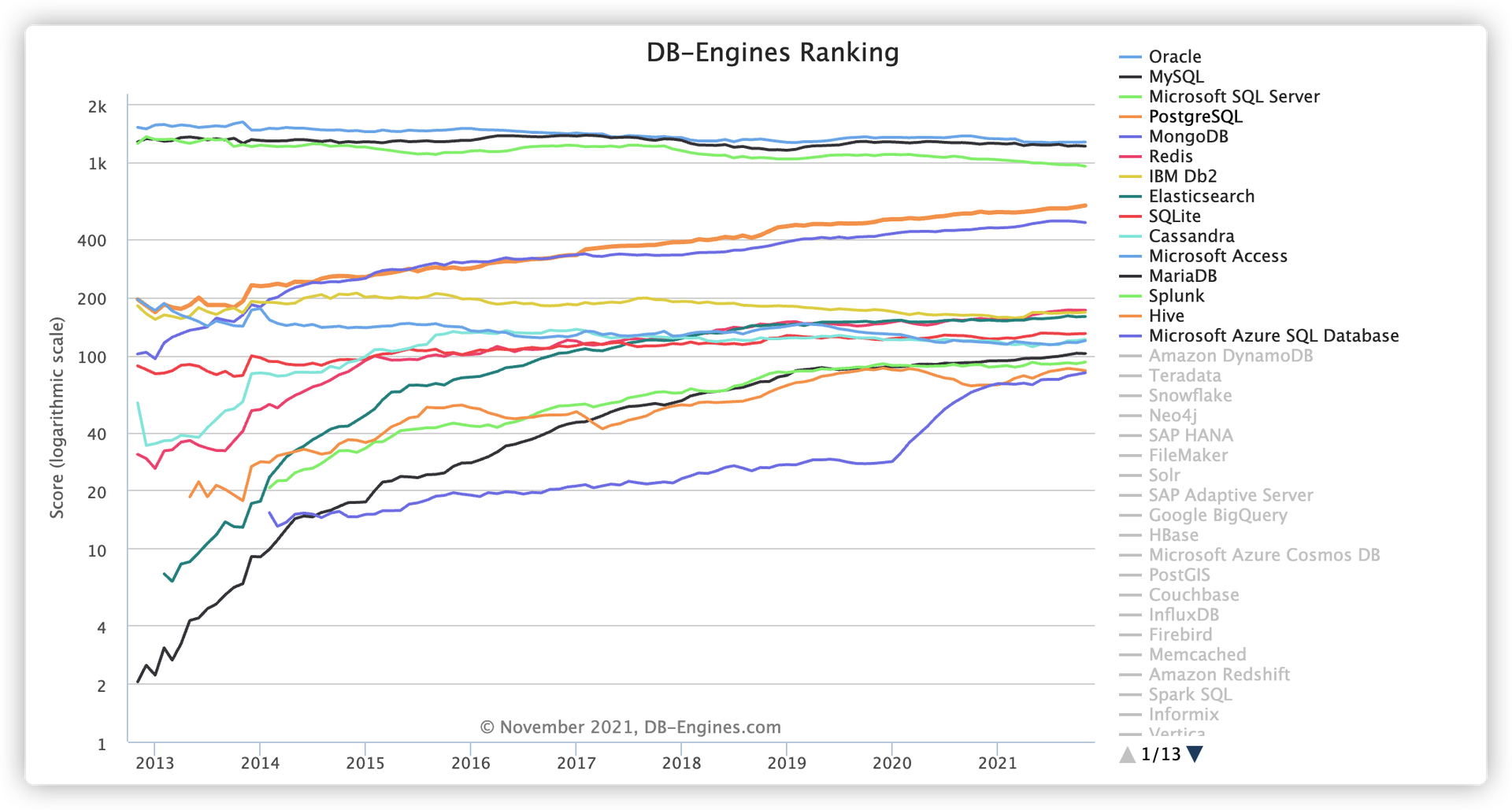
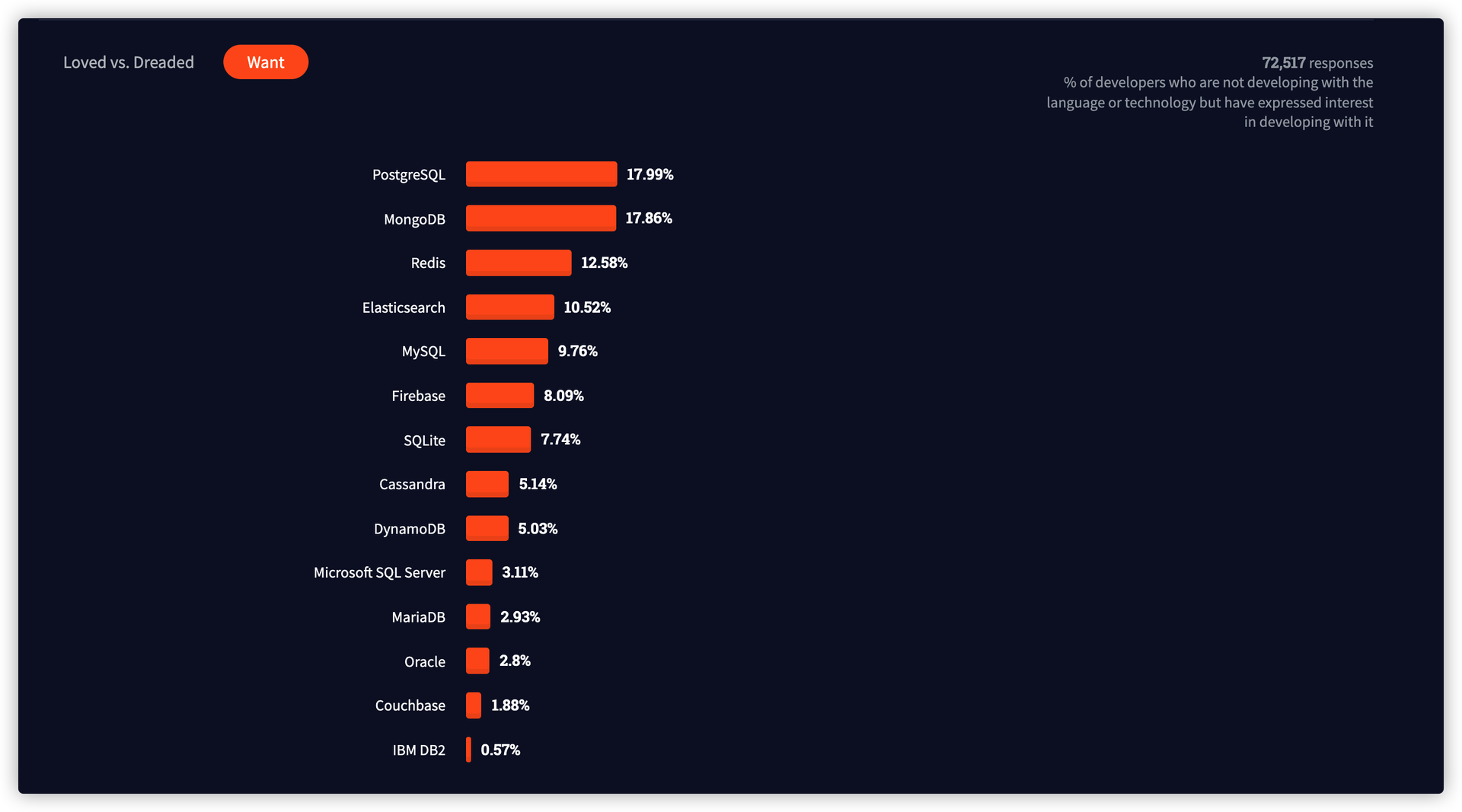
Stack Overflow 问卷调查
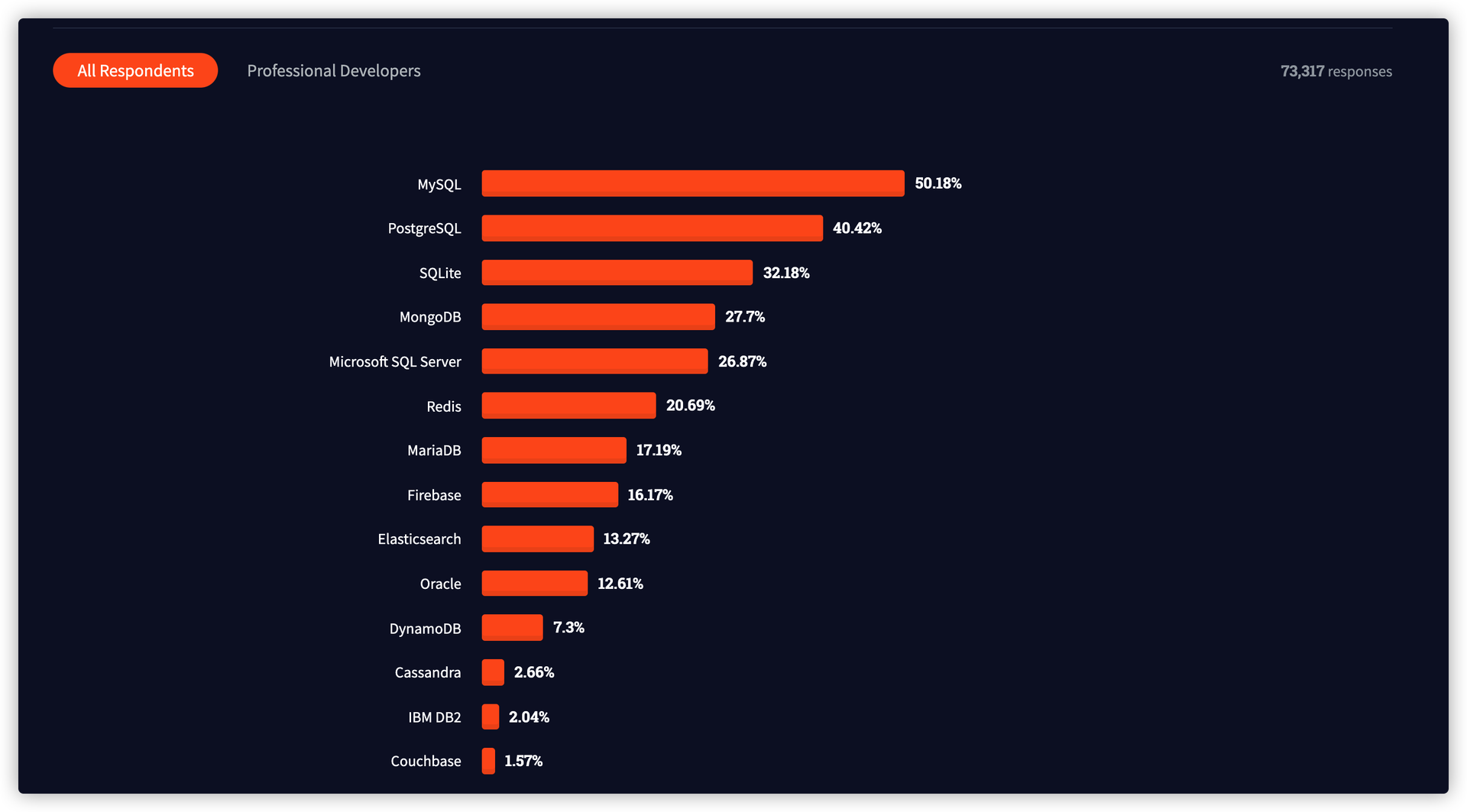
PG功能
SQL标准
最新的 SQL 标准是 SQL:2016
SQL:2016 标准中的核心标准中的179项特性,而 PG 至少实现了170项,在数据库中也算名列前茅的
Schema
Schema定义
一个 PG 集群可以包含多个数据库,一个数据库包含一个或多个命名模式,模式中包含着表
schema 还包含其他类型的命名对象,包括数据类型、函数和操作符。相同的对象名称可以被用于不同的模式中而不会出现冲突,例如 schema1 和 myschema 都可以包含名为 mytable 的表
下面是一些使用 schema 的原因:
- 允许多个用户使用一个数据库并且不会互相干扰
- 将数据库对象组织成逻辑组以便更容易管理
- 第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突
schema 类似于操作系统层的目录,但是 schema 不能嵌套
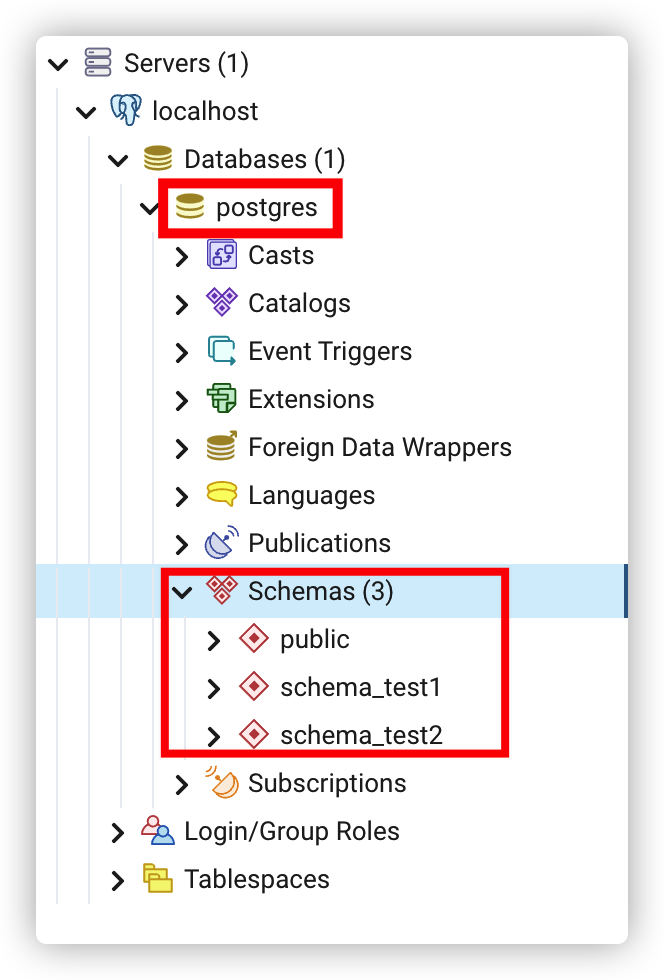
默认情况下,新创建的数据库有一个 public 的模式,但可以添加任何其他模式,并且 public 模式不是必需的
Schema使用
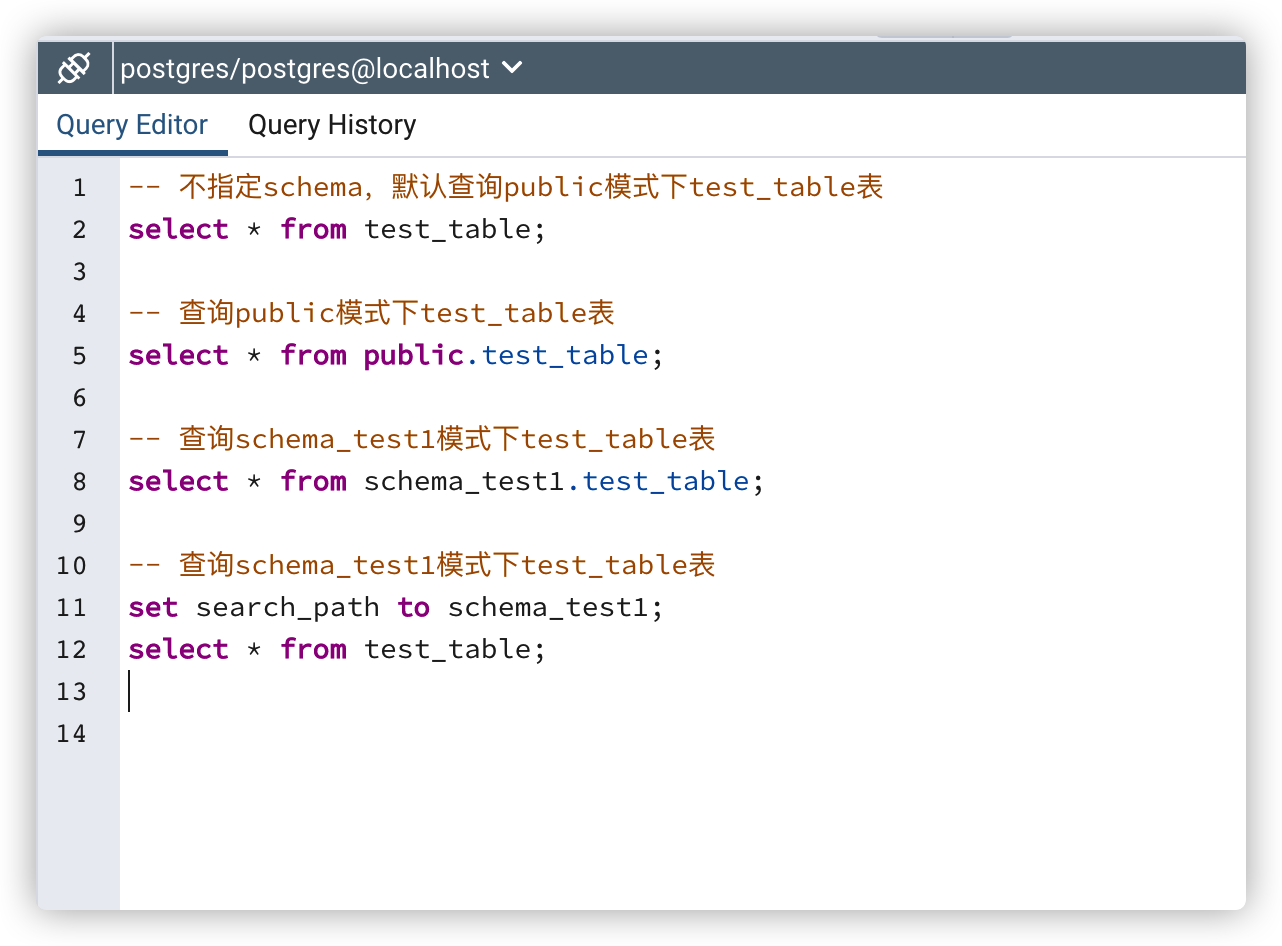
在 SQL 中需要在表名前添加 schema 前缀,如不添加则默认是 public 模式,或使用 search_path 指定 schema
数据类型
PG 支持非常丰富的数据类型,下面是普通数据类型,同时下面所有普通数据类型都支持数组类型
| 名字 | 别名(曾经使用过) | 描述 |
|---|---|---|
| bigint | int8 | 有符号的8字节整数 |
| bigserial | serial8 | 自动增长的8字节整数 |
| bit [ (n) ] | 定长位串 | |
| bit varying [ (n) ] | varbit [ (n) ] | 变长位串 |
| boolean | bool | 逻辑布尔值(真/假) |
| box | 平面上的普通方框 | |
| bytea | 二进制数据(“字节数组”) | |
| character [ (n) ] | char [ (n) ] | 定长字符串 |
| character varying [ (n) ] | varchar [ (n) ] | 变长字符串 |
| cidr | IPv4或IPv6网络地址 | |
| circle | 平面上的圆 | |
| date | 日历日期(年、月、日) | |
| double precision | float8 | 双精度浮点数(8字节) |
| inet | IPv4或IPv6主机地址 | |
| integer | int, int4 | 有符号4字节整数 |
| interval [ fields ] [ (p) ] | 时间段 | |
| json | 文本 JSON 数据 | |
| jsonb | 二进制 JSON 数据,已分解 | |
| line | 平面上的无限长的线 | |
| lseg | 平面上的线段 | |
| macaddr | MAC(Media Access Control)地址 | |
| macaddr8 | MAC(Media Access Control)地址(EUI-64格式) | |
| money | 货币数量 | |
| numeric [ (p, s) ] | decimal [ (p, s) ] | 可选择精度的精确数字 |
| path | 平面上的几何路径 | |
| pg_lsn | PostgreSQL日志序列号 | |
| pg_snapshot | 用户级事务ID快照 | |
| point | 平面上的几何点 | |
| polygon | 平面上的封闭几何路径 | |
| real | float4 | 单精度浮点数(4字节) |
| smallint | int2 | 有符号2字节整数 |
| smallserial | serial2 | 自动增长的2字节整数 |
| serial | serial4 | 自动增长的4字节整数 |
| text | 变长字符串 | |
| time [ (p) ] [ without time zone ] | 一天中的时间(无时区) | |
| time [ (p) ] with time zone | timetz | 一天中的时间,包括时区 |
| timestamp [ (p) ] [ without time zone ] | 日期和时间(无时区) | |
| timestamp [ (p) ] with time zone | timestamptz | 日期和时间,包括时区 |
| tsquery | 文本搜索查询 | |
| tsvector | 文本搜索文档 | |
| txid_snapshot | 用户级别事务ID快照(废弃; 参见 pg_snapshot) | |
| uuid | 通用唯一标识码 | |
| xml | XML数据 |
PG 还可以自定义数据类型,用户可以使用CREATE TYPE命令为 PostgreSQL增加新的数据类型
索引
索引类型
PG 提供了多种索引类型: B-tree、Hash、GiST、SP-GiST 、GIN 和 BRIN
B-tree可以在可排序数据上的处理等值和范围查询Hash索引只能处理简单等值比较GiST索引并不是一种单独的索引,是一个通用的索引接口SP-GiST类似GiST,是一个通用的索引接口,但是SP-GIST使用了空间分区的方法,使得SP-GiST可以更好的支持非平衡数据结构,例如四叉树、k-d树和radix树GIN索引是“倒排索引”,它适合于包含多个组成值的数据值,例如数组BRIN索引是块级索引,有别于B-TREE等索引,BRIN 记录并不是以行号为单位记录索引明细,而是记录每个数据块或者每段连续的数据块的统计信息因此
BRIN索引空间占用特别的小,对数据写入、更新、删除的影响也很小被索引列的值与物理存储相关性很强时,BRIN 索引的效果非常的好。例如时序数据,在时间或序列字段创建
BRIN索引,进行等值、范围查询时效果很棒
用户可以通过索引接口自定义索引
所以除上面的内置索引外,还有许多自定义索引,可以根据需求安装其他索引
部分索引
部分索引 又习惯称 条件索引
一个条件索引是建立在表的一个子集上,而该子集则由一个条件表达式定义
而索引中只包含那些符合条件表达式的行。条件索引是一种专门的特性,但在很多种情况下它们也很有用
使用场景:
多租户的场景下,数据存在一个表中,不同租户存储的数据不同,使用场景不同,可以根据不同租户场景建立条件索引
表达式索引
部分索引 又习惯称 函数索引
一个索引列并不一定是底层表的一个列,也可以是从表的一列或多列计算而来的一个函数或者标量表达式
过程语言
Procedural Language(过程语言)简称 PL
几乎每个关系型数据库都有自己的PL实现,比如 Oracle 的 PL/SQL、SQL Server 的 T-SQL,而在 PG 中,提供的就是 PL/pgSQL
但是 PG 的 PL 支持多种语言,如下:
- PL/Java
- PL/PHP
- PL/Perl
- PL/Python
- PL/V8(JavaScript)
PostGIS
PostGIS介绍
PostGIS 是 PG 的一个空间对象扩展模块
PostGIS 通过向 PG 添加对空间数据类型、空间索引和空间函数的支持,使其成为一个真正的大型空间数据库
PostGIS 使 PG 目前成为开源空间信息软件领域性能最优的数据库
PostGIS特性与功能
PostGIS支持所有的空间数据类型这些类型包括:点(POINT)、线(LINESTRING)、多边形(POLYGON)、多点 (MULTIPOINT)、多线(MULTILINESTRING)、多多边形(MULTIPOLYGON)和集合对象集 (GEOMETRYCOLLECTION)等
PostGIS支持所有的对象表达方法比如WKT和WKB。
PostGIS支持所有的数据存取和构造方法如GeomFromText()、AsBinary(),以及GeometryN()等
PostGIS提供简单的空间分析函数如Area和Length
同时也提供其他一些具有复杂分析功能的函数
比如Distance。
PostGIS提供了对于元数据的支持如GEOMETRY_COLUMNS和SPATIAL_REF_SYS
同时,PostGIS也提供了相应的支持函数
如AddGeometryColumn和DropGeometryColumn。
PostGIS提供了一系列的二元谓词(如Contains、Within、Overlaps和Touches)用于检测空间对象之间的空间关系,同时返回布尔值来表征对象之间符合这个关系PostGIS提供了空间操作符(如Union和Difference)用于空间数据操作比如,Union操作符融合多边形之间的边界。两个交迭的多边形通过Union运算就会形成一个新的多边形,这个新的多边形的边界为两个多边形中最大边界
数据库坐标变换
球体长度运算
三维的几何类型
空间聚集函数
栅格数据类型
……
PostGIS 的功能非常强大,PG 有目前的影响力 PostGIS 功不可没~
PG的特殊能力
用户自定义对象
用户可以创建数据库中几乎所有对象的新类型,包括但不限于:
- 自定义数据类型
- 自定义类型转换
- 自定义操作符
- 自定义函数,包括聚合函数和窗口函数
- 自定义索引
- 自定义过程语言
窗口函数
一个窗口函数在一系列与当前行有某种关联的表行上执行一种计算。这与一个聚集函数所完成的计算有可比之处。但是窗口函数并不会使多行被聚集成一个单独的输出行,这与通常的非窗口聚集函数不同。取而代之,行保留它们独立的标识。在这些现象背后,窗口函数可以访问的不仅仅是查询结果的当前行。
- 可以访问与当前记录相关的多行记录;
- 不会使多行聚集成一行, 与聚集函数的区别;
例如结合窗口函数得到总行数
1 | select * from testtable; |
其他
其他
PG 还有许多特殊的能力,只有想不到的,没有做不到的
表继承
触发器不光可以拦截 DML 还可以拦截 DDL 语句
时序数据支持
分区表
外部数据源FDW,PG 中可以引用多种外部数据,包括MySQL、Oracle等主流关系型数据库,甚至还支持Redis、MongoDB等非关系型数据库
……
PG、MySQL对比
数据表存储结构对比
堆表(heap table)和索引组织表(Index Oragnization Table,简称IOT)是两种数据表的存储结构
PG 中的表是堆表。MySQL Innodb引擎中的表是索引组织表
堆表
堆表的特点就是索引和数据分开存储
表数据行在堆中存储,没有任何特定顺序,向一个全新的没有做过更新和删除的堆中插入一行时候,总是 append 到堆表文件的最后一页当中。因为不用考虑排序,所以插入速度会比较快。
索引存储在索引里,所有索引都是二级索引,或叫辅助索引。所以主键索引也是二级索引,没有完整记录,区别只有唯一或非唯一
优点:写入速度快、辅助索引查询较快、全表扫描快
缺点:磁盘空间消耗较大、主键查询较慢,需要先按主键索引找到数据的物理位置、
索引组织表
索引组织表特点是数据和主键索引一起存储
数据存储在聚簇索引中,或者说,数据按照主键的顺序来组织数据,两者合二为一。主键索引,叶子节点存放整行数据。其他索引称为辅助索引(二级索引),叶子节点存放键值和主键值
优点:主键查询比较快、比较节约磁盘、更新效率更高
缺点:二级索引查询慢,需要回表
MVCC对比
MVCC的两种实现方法:
当写入新数据时,把原有数据转移到一个单独的地方,如undo段中,其他人读数据时,会读取undo中的旧数据
当写入新数据时,原有数据不删除,而是把新数据插入,在不同版本的原有数据不需要时,垃圾回收器将回收这些过期的数据
MySQL:
MySQL采用的就是第一种方式,详细不在说明
PG:
PG 采用的第二种方式,数据文件中存放着每一逻辑行的多个版本,问题随之而来,表空间会非常容易膨胀
为了解决表空间膨胀的问题,PG 采用 VACUUM 方式,来回收历史数据,且需要定期手动进行 VACUUM
性能对比
任何系统都有它的性能极限,在高并发读写,负载逼近极限下,PG的性能指标仍可以维持双曲线甚至对数曲线,到顶峰之后不再下降,而 MySQL 明显出现一个波峰后下滑(5.5版本之后,在企业级版本中有个插件可以改善很多,不过需要付费)
其他对比
| 特性 | PG | MySQL |
|---|---|---|
| 口号性特点 | 最先进的开源数据库 | 最流行的开源数据库 |
| SQL编程能力 | 强大的SQL能力,包括丰富的统计函数和统计分析,对BI 有很好的支持 | 没有强大的统计功能支持 |
| 数据类型 | 丰富的数据类型支持,包括地理信息、几何图形、 json、数组等,json也可以建立索引 | 在地理信息支持度上不如PG,不支持几何图形等数据 类型 |
| 事务能力 | 完整的ACID事务支持 | 不是完整的支持ACID事务特性 |
| join | 支持nested-loop, sort-merge, hash三种类型 | 只支持nested-loop |
| Text类型 | 没有长度限制,可以直接访问,可以索引,可以全文索 引 | 有长度限制 |
| 复杂查询 | 支持窗口函数,支持递归,支持with语句 | 不支持窗口函数、递归等 |
| 索引 | 多种索引类型,包括b-tree,hash,gin,gist等,可以 对模糊查询、正则表达式、地理信息系统等建立索引 | 主要是b-tree索引 |
| 数据复制 | 同步,异步,半同步复制,以及基于日志逻辑复制,可以实现表级别的订阅和发布 | 只支持异步复制 |
| 查询优化器 | 功能更强大,对子查询的支持更高效 | 子查询效率不高 |
| 7*24 | 隔一段时间需要进行VACUUM | 适用7*24 |
| 性能和适用场景 | 复杂查询 | 简单业务场景,更高的TPS |
| 大小写 | 大小写敏感 | 大小写不敏感 |
| 行大小限制 | 无限制 | 65535 |
参考资料
官方文档
PG中文社区
PG官方客户端工具
PG相关高质量博客

